Расположите аэропорты по убыванию года их открытия: Работа администратором соц. сетей за сегодня, без высшего образования, вакансии в Раменском на SuperJob
Работа администратором соц. сетей за сегодня, без высшего образования, вакансии в Раменском на SuperJob
Сегодня в 9:35
Администратор магазина (Россия, Московская обл, г Раменское, тер автодорога Егорьевское шоссе (село Новохаритоново), д 217)
36 936 — 50 000 ₽/месяц
Добавить в избранное
Пятёрочка
Раменское
Отклик без резюме
Организация работы магазина. Контроль работы сотрудников. Выполнение плана по товарообороту…
Образование не ниже среднего профессионального. Управленческий опыт работы от 0,…
Скидки в магазинах сети. Медицинская страховка (в формате телемедицины)
В компании есть ещё 643 похожие вакансии
Скрыть
Администратор магазина
48 000 — 55 000 ₽/месяц
Добавить в избранное
АШАН Ритейл Россия7
Раменское
Организация работы в выделенном отделе. Аналитика продаж; осуществление заказов. Контроль наличия товара и его остатков
Успешный опыт работы в розничной торговле от 1 года на аналогичной должности
В компании есть ещё 9 похожих вакансий
Смотрят1 человекСкрыть
Администратор магазина Первый выбор (Раменское, Полушкино, Ясная поляна, 105)
55 000 — 65 000 ₽/месяц
Добавить в избранное
Магнит, Розничная сеть
Раменское
Отклик без резюме
Постановка задач персоналу на смену, контроль выполнения. Контроль запасов товаров и их сохранности. Контроль расстановки товаров
Контроль запасов товаров и их сохранности. Контроль расстановки товаров
Опыт работы от 6 месяцев. Образование не ниже средне-специального
В компании есть ещё 5 похожих вакансий
Смотрят1 человекСкрыть
Разместите резюме, и мы подберем вам подходящие вакансии
Администратор магазина (Россия, Московская обл, г Раменское, село Никулино, д 35)
47 037 — 60 000 ₽/месяц
Добавить в избранное
Пятёрочка
Раменское
Отклик без резюме
Организация работы магазина. Контроль работы сотрудников. Выполнение плана по товарообороту…
Образование не ниже среднего профессионального. Управленческий опыт работы от 0,…
Скидки в магазинах сети. Медицинская страховка (в формате телемедицины)
В компании есть ещё 428 похожих вакансий
Скрыть
Вакансии из соседних городов
Сегодня в 10:18
Администратор торгового зала (старший сотрудник супермаркета)
35 000 — 41 000 ₽/месяц
Добавить в избранное
Перекрёсток6. 6
6
Москва
Отклик без резюме
Контроль оформления торгового зала, полноты выкладки, размещения и обновления товаров. Консультирование покупателей и помощь…
Желание заботиться о клиенте. Грамотная речь и коммуникабельность
В компании есть ещё 23 похожие вакансии
Скрыть
Получайте новые вакансии по вашему запросу
администратор сетей соц. / Раменское / Не требующие высшего образованияСегодня в 10:15
Администратор магазина
38 500 — 46 000 ₽/месяц
Добавить в избранное
FIX PRICE
Климовск
Контроль работы грузчиков…
Fix Price — международная сеть магазинов для всей семьи с широким ассортиментом товаров для дома по низким фиксированным ценам приглашает кандидатов на вакансию «Администратор» (Старший Продавец — Кассир) в Климовске
В компании есть ещё 18 похожих вакансий
Смотрят1 человекСкрыть
Сегодня в 10:10
Администратор почтового отделения
от 29 000 ₽/месяц
Добавить в избранное
Почта России
Мытищи
Отклик без резюме
Опыт не нужен
Встреча клиентов, первичное консультирование. Распределение потоков клиентов к соответствующим…
Распределение потоков клиентов к соответствующим…
Образование не ниже средне-специального. Знание компьютера и оргтехники
Полная социальная защищенность. Стабильный фиксированный оклад 29.000 руб
В компании есть ещё 2 похожие вакансии
Скрыть
Сегодня в 10:05
Администратор супермаркета (пр. Будённого)
от 62 000 ₽/месяц
Добавить в избранное
ООО «Лента»6.9
Москва
Шоссе Энтузиастов
Соколиная Гора
Отклик без резюме
Контроль операционной деятельности супермаркета и управление товарным ассортиментом
Образование не ниже средне-специального
«ЛЕНТА», одна из крупнейших федеральных розничных сетей России, приглашает на должность Администратор супермаркета
В компании есть ещё 24 похожие вакансии
Смотрят1 человекСкрыть
Сегодня в 9:30
Администратор в пункт выдачи заказов
45 000 — 50 000 ₽/месяц
Добавить в избранное
СДЭК6.9
Москва
4 минутыПолежаевская
Опыт не нужен
Консультировать клиента лично и по телефону: сроки доставки, стоимость, местоположение. Принимать и выдавать посылки в офисе
Принимать и выдавать посылки в офисе
Грамотная речь и четкая дикция. Вы умеете расположить к себе и точно донести мысль
Скрыть
Сегодня в 9:30
Администратор розничного магазина
56 000 — 67 000 ₽/месяц
Добавить в избранное
Азбука вкуса7.2
Москва
15 минутДобрынинская
12 минутСерпуховская
Азбука вкуса
Контролировать работу в торговом зале — выкладку товара и качество обслуживания покупателей
Работал администратором / зам. директора / директором в сетевых компаниях не менее года. Благодарим за интерес к «Азбуке вкуса»
Скрыть
Сегодня в 9:19
Администратор магазина (Мега Белая Дача)
до 70 000 ₽/месяц
Добавить в избранное
Снежная Королева
Москва
Организовывать эффективную работу магазина
Высокую ориентацию на результат
«СНЕЖНАЯ КОРОЛЕВА» — это лучшая сеть магазинов мехов и верхней одежды, которая включает более 120 магазинов по всей стране и в которой работает более 3500 человек
В компании есть ещё 1 похожая вакансия
Смотрят1 человекСкрыть
Сегодня в 7:51
Администратор медцентра (м. Таганская)
Таганская)
до 60 000 ₽/месяц
Добавить в избранное
Мобил. Мед7.4
Москва
Работа с клиентами. Выдача медицинских книжек, справок, лабораторных анализов. Работа…
Уверенный пользователь ПК. Знание MS Office, навыки работы с орг.техникой
Спец.цены для сотрудников в сети мед.центров
Скрыть
Сегодня в 7:50
Старший специалист связи
По договорённости
Добавить в избранное
Группа Полюс
Москва
Опыт работы системным/сетевым администратором от 3 лет. Знание пакета приложений MS Office на уровне опытного пользователя
Трудоустройство в соответствии с нормами ТК РФ, социальные гарантии. Конкурентный уровень заработной платы
Скрыть
Сегодня в 5:35
Администратор хостела
до 60 000 ₽/месяц
Добавить в избранное
Гаврилов Иван Андреевич
Москва
Смоленская
Опыт не нужен
Прием и оформление гостей, наведение и поддержание порядка, смена постельного белья, ведение отчетной документации, решение…
Знание ПК, доброжелательность, стрессоустойчивость, грамотная речь, порядочность, опрятный внешний вид
Скрыть
Сегодня в 2:24
Старший администратор
до 28 000 ₽/месяц
Добавить в избранное
Московская государственная консерватория имени П. И. Чайковского
И. Чайковского
Москва
Старший администратор Студенческого комплекса Консерватории обязан. Контролировать содержание жилых комнат и помещений общего…
Скрыть
Администратор (оператор ЭВМ) приемного отделения
По договорённости
Добавить в избранное
ГБУЗ МО «Долгопрудненская центральная больница»
Москва
Прием и оформление поступающих в приемное отделение пациентов
Опыт работы на компьютере, коммуникабельность, стрессоустойчивость
Скрыть
Администратор
35 000 — 45 000 ₽/месяц
Добавить в избранное
Москва
Крылатское
Молодежная
Опыт не нужен
Прием звонков и запись клиентов. Консультация клиентов по оказываемым услугам лично и по телефону. Создание комфортных условий…
Пунктуальность. Вежливость. Стрессоустойчивость. Опыт обращения с ПК…
Скрыть
Администратор склада
от 61 000 ₽/месяц
Добавить в избранное
Леруа Мерлен Восток
Коммунарка
Отклик без резюме
Доступно для соискателей с ограниченными возможностями
Доступно студентам
Организация сборки и выдачи товара (offline/online заказов). Обеспечивать качественную…
Обеспечивать качественную…
Аналитические способности. Внимательность к деталям и оперативность
Расширенный социальный пакет. Корпоративный транспорт (утренняя, вечерняя доставка…
В компании есть ещё 4 похожие вакансии
Скрыть
Администратор в клуб
50 000 — 70 000 ₽/месяц
Добавить в избранное
КОСМИК — центры развлечений
Москва
Открытие и закрытие смены по чек-листам. Координация и контроль за работой подразделений клуба (ресторан, кухня, технические…
Образование средне-специальное и выше. Опыт работы в ресторанах полного обслуживания…
В компании есть ещё 1 похожая вакансия
Смотрят4 человекаСкрыть
Секретарь/администратор
По договорённости
Добавить в избранное
Работа для всех
Москва
Добрынинская
Опыт не нужен
Будьте первым
Ведение социальных сетей компании
Ответственное отношение к работе. Уверенный пользователь MS Office. Грамотная письменная и устная речь. Коммуникабельность…
Коммуникабельность…
В компании есть ещё 1 похожая вакансия
Смотрят4 человекаСкрыть
Приемщик / Администратор в химчистку (Площадь Ильича)
от 1700 ₽/день
Добавить в избранное
Объединение «Диана»
Москва
Площадь Ильича
Опыт не нужен
Прием, оформление и выдача заказов на приемном пункте. Консультирование клиентов по условиям, акциям, и дополнительным услугам…
Внимательность, ответственность, доброжелательность, стремление к обучению
В компании есть ещё 3 похожие вакансии
Смотрят1 человекСкрыть
Администратор медицинского центра
от 60 000 ₽/месяц
Добавить в избранное
КосМос
Москва
Информирование пациентов об услугах, предоставляемых в клинике, продаваемой космецевтике, их стоимости, специальных предложениях…
Среднее профессиональное / высшее образование. Действующая медицинская…
Скрыть
Администратор медицинской клиники
от 45 000 ₽/месяц
Добавить в избранное
КВМ (Клиника Восстановительная медицина)
Королев
Ответы на телефонные запросы пациентов, консультации по вопросам услуг клиники, запись на прием. Встреча пациентов, координация…
Встреча пациентов, координация…
Любовь к людям. Коммуникабельность. Отличное владение русским языком
Скрыть
Разместите резюме, и мы подберем вам подходящие вакансии
Администратор медицинского центра
50 000 — 75 000 ₽/месяц
Добавить в избранное
Сеть медицинских клиник Goldenmed
Видное
Консультирование пациентов по услугам клиники. Работа за ресепшн. Запись пациентов на прием. Расчетно-кассовые операции
Грамотная речь. Вежливость, опрятность. Высокий уровень ответственности
В компании есть ещё 4 похожие вакансии
Смотрят4 человекаСкрыть
Администратор стойки информации ТЦ
от 45 000 ₽/месяц
Добавить в избранное
ПИПЛ МЕДИА ПРОДАКШЕН
Москва
Будьте первым
ТОЛЬКО ДЕВУШКИ, приятной внешности, без татуировок, пирсинга на открытых участках тела. Возраст от 21 до 30 лет. Образование…
Скрыть
Администратор торгового зала на АЗС (м. Котельники)
Котельники)
от 45 000 ₽/месяц
Добавить в избранное
Стопэкспресс
Москва
Котельники
Жулебино
Приемка, предпродажная подготовка, выкладка, продажа товара. Помощь управляющему…
Энергичность, ответственность, доброжелательность, позитивность, готовность делиться…
Социальные гарантии (оплачиваемый отпуск 2 раза в год, больничный и т.д.). Оплачиваемое…
В компании есть ещё 1 похожая вакансия
Скрыть
Администратор-контролер КПП
50 000 — 54 000 ₽/вахта 30 дней
Добавить в избранное
GSR РАБОТА
Железнодорожный
Будьте первым
Вахта
Проверка работников по пропускам и транспорта перед проходом (въездом) на территорию. Контроль соблюдения установленных правил…
Качества: вежливость, тактичность, честность, порядочность, открытость
В компании есть ещё 23 похожие вакансии
Скрыть
Администратор отеля
50 000 ₽/месяц
Добавить в избранное
Зона отдыха «Троицкое»
Москва
Обеспечивает работу по эффективному и культурному обслуживанию посетителей, созданию для них комфортных условий. Осуществляет…
Осуществляет…
Знание программы бронирования для гостиниц. Ответственность, исполнительность…
Скрыть
Продавец-консультант, Администратор в магазин
от 34 000 ₽/месяц
Добавить в избранное
Параватов Никита Андреевич
Фрязино
Опыт не нужен
Будьте первым
Консультирование и обслуживание покупателей. Демонстрация товара. Оказание помощи в выборе товара. Работа на кассе
Уверенный пользователь ПК. Коммуникабельность, ответственность, вежливость
Скрыть
Администратор зала
45 000 — 50 000 ₽/месяц
Добавить в избранное
Балашиха
Регистрация посетителей зала «Комфорт». Работа с контрольно-кассовым оборудованием
Образование средне-профессиональное или высшее. Опыт работы на контрольно-кассовой…
СОЦИАЛЬНЫЙ ПАКЕТ. Медицинское обслуживание в клиниках РЖД, ДМС
В компании есть ещё 2 похожие вакансии
Смотрят1 человекСкрыть
Оператор справочно-координационной службы
от 65 000 ₽/месяц
Добавить в избранное
«Сеть медицинских клиник «ИММА. РУ» («IMMA.RU»)
РУ» («IMMA.RU»)
Москва
Опыт не нужен
Будьте первым
Консультативная помощь администраторам клиник … МИС. Работа с медицинскими информационными системами и эл. почтой сети медицинских клиник
Соц. пакет – льготное медицинское обслуживание сотрудников и членов их семей. Ежегодные премии за стаж работы…
Скрыть
Администратор стоматологической клиники
от 40 000 ₽/месяц
Добавить в избранное
ООО»Свобода»
Москва
Уверенный пользователь ПК, грамотная речь. Опыт работы от 1 года в стоматологии
Скрыть
Администратор в стоматологическую клинику
40 000 — 60 000 ₽/месяц
Добавить в избранное
ЮНИДЕНТ — Стоматология5.6
Москва
Прием звонков, запись пациентов к врачам по расписанию, обслуживание пациентов в центре, ведение электронной и бумажной документации…
Опыт работы в стоматологии. Приятная внешность , грамотная речь
Скрыть
Бригадир, администратор
50 000 — 70 000 ₽/месяц
Добавить в избранное
Москва
Распределение заданий и участков выполнения уборки между сотрудниками компании. Ведение учета инвентаря, оборудования, моющих…
Ведение учета инвентаря, оборудования, моющих…
Опыт работы в аналогичной должности от 1 года. Знать санитарные и гигиенические…
Скрыть
Администратор в стоматологию
от 40 000 ₽/месяц
Добавить в избранное
Киви-Дент
Москва
8 минутКоломенская
Встреча пациентов. Заполнение документации. Обзвон. Работа в базе
Умение работать на компьютере. Стрессоустойчивость. Желание работать
Скрыть
Администратор службы приема и размещения
33 000 — 38 000 ₽/месяц
Добавить в избранное
Москва
Речной вокзал
Отклик без резюме
Опыт не нужен
Будьте первым
Прием и размещение гостей. Оформление документов для регистрации иностранных гостей. Кассовая документация. Прием и распределение…
Грамотная речь. Ответственность. Исполнительность. Дополнительные…
Скрыть
Администратор медицинского центра
42 000 — 65 000 ₽/месяц
Добавить в избранное
Профессорский медицинский центр «Исида»
Мытищи
Работа в программе «Инфодент». Запись на прием и консультирование по услугам клиники пациентов. Сопровождение детей и родителей…
Запись на прием и консультирование по услугам клиники пациентов. Сопровождение детей и родителей…
Образование не ниже среднего специального. Знание компьютера и оргтехники
В компании есть ещё 1 похожая вакансия
Смотрят1 человекСкрыть
Администратор стоматологической клиники
50 000 — 70 000 ₽/месяц
Добавить в избранное
Дентал Студио
Москва
Опыт не нужен
Работа в специализированной программе с клиентской базой. Координирование записи пациентов к специалистам. Встреча и размещение…
Умение мотивировать пациентов на запись к специалистам клиники
Скрыть
Администратор магазина
от 55 000 ₽/месяц
Добавить в избранное
Гаврюшина Анна Анатольевна
Москва
Управление персоналом: мотивация, обучение персонала, постановка задач и контроль…
Наличие опыта продаж от 3 лет на одном рабочем месте
Социальный пакет (ДМС со стоматологией после прохождения испытательного срока). Мы…
Мы…
Скрыть
Администратор-кассир медицинского центра
от 45 000 ₽/месяц
Добавить в избранное
Москва
7 минутКоломенская
Опыт не нужен
Запись на прием пациентов
Уверенный пользователь ПК. Грамотная речь. Умение работать с кассовым аппаратом
В компании есть ещё 1 похожая вакансия
Смотрят1 человекСкрыть
123ДальшеДомашнее задание-2
Некоторые определяют статистику как область, которая фокусируется на токарной обработке.
информацию в знания. Первым шагом в этом процессе является
обобщать и описывать необработанную информацию – данные. В этом домашнем задании
мы изучим рейсы, в частности, случайную выборку внутренних
рейсов, вылетавших из трех крупных аэропортов Нью-Йорка в
2013. Мы будем генерировать простые графические и числовые сводки данных
на этих рейсах и узнать время задержки. Поскольку это большой набор данных,
попутно вы также освоите необходимые навыки работы с данными
обработка и поднастройка.
библиотека(tidyverse) library(openintro)
Набор данных nycflights13 представляет собой набор данных, относящихся к разные авиакомпании летают из разных аэропортов Нью-Йорка (Нью-Йорк), а также захват информации о полете, самолете и погоде во время 2013 года. Данные были собраны в эти пять различных ветви. Этот метод сбора данных помогает нам работать над отдельными аспекты всего большого набора данных, а также мы можем объединить вместе несколько аспектов для проведения сложного анализа данных. Есть и 3-4 версии базы данных набора данных nycflights, которые кэшируют данные из база данных nycflights в локальной базе данных, что помогает объединять таблицы на естественные ключи эффективно. Источником набора данных о рейсах является BTS Bureau. транспортной статистики.
Для начала взглянем на данные.
- Без выхода
nycflights
- С выходом
При просмотре выходных данных набор данных ( кадр данных R имя) содержат 16 столбцов и 32 735 строк 32 735 х 16 .
nycflights
## # Таблица: 32 735 x 16 ## год месяц день dep_time dep_delay arr_time arr_delay перевозчик tailnum #### 1 2013 6 30 940 15 1216 -4 ВХ Н626ВА ## 2 2013 5 7 1657 -3 2104 10 DL N3760C ## 3 2013 12 8 859 -1 1238 11 ДЛ N712TW ## 4 2013 5 14 1841 -4 2122 -34 DL N914DL ## 5 2013 7 21 1102 -3 1230 -8 9E N823AY ## 6 2013 1 1 1817 -3 2008 3 АА N3AXAA ## 7 2013 12 9 1259 14 1617 22 WN N218WN ## 8 2013 8 13 1920 85 2032 71 Б6 Н284ДЖБ ## 9 2013 9 26 725 -10 1027 -8 АА N3FSAA ## 10 2013 4 30 1323 62 1549 60 ЭВ N12163 ## # ... с еще 32 725 строками и еще 7 переменными: Flight , origin , ## # dest , air_time , Distance , hour , minute
Для просмотра имен переменных введите команду
name(nycflights)
## [1] "год" "месяц" "день" "время_отгрузки" "время_задержки" "время_прибытия" ## [7] "arr_delay" "carrier" "tailnum" "flight" "origin" "dest" ## [13] "air_time" "расстояние" "час" "минута"
Возвращает имена переменных в этом фрейме данных. кодовая книга (описание переменных) доступна
открыв файл справки:
кодовая книга (описание переменных) доступна
открыв файл справки:
?nycflights
Одна из переменных относится к перевозчику (то есть авиакомпании) рейс, который кодируется по следующей системе.
См. авиакомпании в пакете nycflights13 для получения дополнительной информации или Google код авиакомпании.
Мы также можем проверить размеры этого фрейма данных, а также
имена переменных, тип переменных и первые несколько наблюдений
вставив имя набора данных в glimpse() как показано ниже:
glimpse(nycflights)
## Строки: 32 735 ## Столбцы: 16 ## $ year2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013, ~ ## $ месяц 6, 5, 12, 5, 7, 1, 12, 8, 9, 4, 6, 11, 4, 3, 10, 1, 2, 8, 10~ ## $ день 30, 7, 8, 14, 21, 1, 9, 13, 26, 30, 17, 22, 26, 25, 21, 23, ~ ## $ dep_time 940, 1657, 859, 1841, 1102, 1817, 1259, 1920, 725, 1323, 940~ ## $ dep_delay 15, -3, -1, -4, -3, -3, 14, 85, -10, 62, 5, 5, -2, 115, -4, ~ ## $ arr_time 1216, 2104, 1238, 2122, 1230, 2008, 1617, 2032, 1027, 1549, ~ ## $ arr_delay -4, 10, 11, -34, -8, 3, 22, 71, -8, 60, -4, -2, 22, 91, -6, ~ ## $ Carrier "VX", "DL", "DL", "DL", "9E", "AA", "WN", "B6", "AA", "EV", ~ ## $ tailnum "N626VA", "N3760C", "N712TW", "N914DL", "N823AY", "N3AXAA", ~ ## $ рейс 407, 329, 422, 2391, 3652, 353, 1428, 1407, 2279, 4162, 20, ~ ## $ origin "JFK", "JFK", "JFK", "JFK", "LGA", "LGA", "EWR", "JFK", "LGA~ ## $ dest "LAX", "SJU", "LAX", "TPA", "ORF", "ORD", "HOU", "IAD", "MIA~ ## $ air_time 313, 216, 376, 135, 50, 138, 240, 48, 148, 110, 50, 161, 87,~ ## $ расстояние 2475, 1598, 2475, 1005, 296, 733, 1411, 228, 1096, 820, 264,~ ## $ час 9, 16, 8, 18, 11, 18, 12, 19, 7, 13, 9, 13, 8, 20, 12, 20, 6~ ## $ minute 40, 57, 59, 41, 2, 17, 59, 20, 25, 23, 40, 20, 9, 54, 17, 24~
Задержка отправления
Начнем с изучения распределение задержек отправления всех
полеты с гистограммой.
ggplot(data = nycflights, aes(x = dep_delay)) + geom_histogram()
Эта функция говорит построить dep_delay переменная от
кадр данных nycflights на оси X. Он также определяет geom (сокращение от геометрического объекта), который описывает тип
участка вы будете производить.
Гистограммы, как правило, очень хороший способ увидеть форму одного распределения числовых данных, но эта форма может меняться в зависимости от как данные распределяются между разными бинами.
Мы можем легко определить ширину бина , как мы хотим использовать:
ggplot(data = nycflights, aes(x = dep_delay)) + geom_histogram (ширина ячейки = 30)
Давайте попробуем с большей шириной бина
ggplot(data = nycflights, aes(x = dep_delay)) + geom_histogram(binwidth = 150)
Упражнение-1
Посмотрите внимательно на эти три гистограммы. Как они сравниваются? Являются черты, открытые в одном, скрыты в другом?
Ответ-1:
Меньшая ширина ячейки предоставить более подробную информацию —
самая большая ширина бина скрывает любую полезную информацию.
Мы замечаем, что чем меньше ширина бина , тем лучше
деталь есть. Вторая гистограмма имеет наименьший binwidth , поэтому он отображает данные более подробно.
третья гистограмма имеет наибольшую ширину ширина бина между двумя другими и отображает детали
соответственно (по умолчанию заняло ячейки = 30 ). Хотя
вторая гистограмма показывает наиболее подробную информацию, ширины бина первое кажется правильным и более приятным для глаз
визуализировать данные.
Если вы хотите визуализировать только задержки рейсов в Лос-Анджелес
Анджелес, вам нужно сначала отфильтровать данные по рейсам с
этот пункт назначения ( dest == "LAX" ), а затем сделать гистограмму
задержек вылета только этих рейсов.
lax_flights <- nycflights %>% фильтр (назначение == "LAX") ggplot (данные = lax_flights, aes (x = dep_delay)) + geom_histogram()
Давайте расшифруем эти две команды (хорошо, это может выглядеть как четыре
строки, но первые две физические строки кода на самом деле являются частью
та же команда.
Команда 1: Возьмите кадр данных
nycflights,отфильтруйтедля рейсов, направляющихся в Лос-Анджелес, и сохраните результат как новый фрейм данных с именемlax_flights.-
==означает «если равно». -
LAXзаключен в кавычки, так как это символ нить.
-
Команда 2: в основном тот же вызов ggplot, что и ранее для создания гистограмма, за исключением того, что она использует меньший фрейм данных для полетов направился в Лос-Анджелес вместо всех рейсов.
Логические операторы: Фильтрация определенных
наблюдения (например, полеты из определенного аэропорта) часто
интерес к фреймам данных, где мы могли бы захотеть изучить наблюдения с
отдельные характеристики отдельно от остальных данных. Для этого
вы можете использовать функцию фильтра и серию логических операторов.
-
==означает «равно» -
!=означает «не равно» -
>или<означает «больше» или «меньше». чем» -
>=или<=означает «больше или равно» или «меньше или равно»
Мы также можем получить сводные данные по этим рейсам:
lax_flights %>%
суммировать (mean_dd = среднее (dep_delay),
median_dd = медиана (dep_delay),
п= п()) ## # Таблица: 1 x 3 ## mean_dd median_dd n #### 1 9.78 -1 1583
Обратите внимание, что в функции summary мы создали список
три различных числовых сводки, которые нас интересовали.
имена этих элементов определяются пользователем, например, mean_dd , median_dd , n , и мы можем настроить эти имена
как нам нравится (только не используйте пробелы в своих именах). Расчет этих
сводная статистика также требует, чтобы мы знали вызовы функций. Примечание
что
Расчет этих
сводная статистика также требует, чтобы мы знали вызовы функций. Примечание
что n() сообщает размер выборки.
Сводная статистика: Некоторые полезные вызовы функций для сводная статистика для одной числовой переменной выглядит следующим образом:
- среднее
- медиана
- сд
- вар
- ИКР
- мин
- макс.
Обратите внимание, что каждая из этих функций принимает один вектор в качестве аргумент и возвращает одно значение.
Мы также можем фильтровать по нескольким критериям. Предположим, вы интересует рейсы в Сан-Франциско (SFO) в феврале:
sfo_feb_flights <- nycflights %>% filter(dest == "SFO", month == 2)
Обратите внимание, что вы можете разделить условия запятыми, если хотите
рейсы, которые оба направляются в SFO и в феврале. Если
вас интересуют рейсы с направлением SFO или в феврале вы можете использовать | вместо запятой.
Упражнение-2
Создайте новый фрейм данных, включающий рейсы, направляющиеся в SFO в
Февраль и сохраните этот фрейм данных как sfo_feb_flights . Как
многие рейсы соответствуют этим критериям?
Ответ-2:
sfo_feb_flights <- nycflights %>% фильтр (назначение == "SFO", месяц == 2) glimpse(sfo_feb_flights)
## Строки: 68 ## Столбцы: 16 ## $ year2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013, ~ ## $ месяц 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, ~ ## $ день 18, 3, 15, 18, 24, 25, 7, 15, 13, 8, 11, 13, 25, 20, 12, 27,~ ## $ dep_time 1527, 613, 955, 1928, 1340, 1415, 1032, 1805, 1056, 656, 191~ ## $ dep_delay 57, 14, -5, 15, 2, -10, 1, 20, -4, -4, 40, -2, -1, -6, -7, 2~ ## $ arr_time 1903, 1008, 1313, 2239, 1644, 1737, 1352, 2122, 1412, 1039, ~ ## $ arr_delay 48, 38, -28, -6, -21, -13, -10, 2, -13, -6, 2, -5, -30, -22,~ ## $ Carrier "DL", "UA", "DL", "UA", "UA", "UA", "B6", "AA", "UA", "DL", ~ ## $ tailnum "N711ZX", "N502UA", "N717TW", "N24212", "N76269"", "N532UA", ~ ## $ рейс 1322, 691, 1765, 1214, 1111, 394, 641, 177, 642, 1865, 272, ~ ## $ origin "JFK", "JFK", "JFK", "EWR", "EWR", "JFK", "JFK", "JFK", "JFK~ ## $ dest "SFO", "SFO", "SFO", "SFO", "SFO", "SFO", "SFO", "SFO", "SFO~ ## $ air_time 358, 367, 338, 353, 341, 355, 359, 338, 347, 361, 332, 351, ~ ## $ Distance 2586, 2586, 2586, 2565, 2565, 2586, 2586, 2586, 2586, 2586, ~ ## $ час 15, 6, 9, 19, 13, 14, 10, 18, 10, 6, 19, 8, 10, 18, 7, 17, 1~ ## $ minute 27, 13, 55, 28, 40, 15, 32, 5, 56, 56, 10, 33, 48, 49, 23, 2~
Всего в феврале в SFO было отправлено 68 рейсов .
Упражнение-3
Описать распределение прибытия задержек эти полеты с использованием гистограммы и соответствующей сводной статистики. Подсказка: Используемая сводная статистика должна зависеть от форма распределения.
Ответ-3:
ggplot(data = sfo_feb_flights, aes(x = arr_delay)) + geom_histogram(binwidth=10)
Гистограмма скошена вправо, поэтому стандартное отклонение не будет
точно отображать распределение данных. IQR с другой стороны, описывает, как средние 50% данных
распределяется около медианы. Оба значения можно найти ниже.
sfo_feb_flights %>% summarise(mean_ad = mean(arr_delay), median_ad = median(arr_delay), iqr_ad = IQR(arr_delay), n_flights = n())
## # Таблица: 1 x 4 ## mean_ad median_ad iqr_ad n_flights #### 1 -4,5 -11 23,2 68
Еще одним полезным методом является быстрый расчет сводной статистики. для различных групп в нашем фрейме данных. Например, мы можем изменить
команду выше, используя функцию
для различных групп в нашем фрейме данных. Например, мы можем изменить
команду выше, используя функцию group_by , чтобы получить то же самое
сводная статистика для каждого аэропорта отправления:
sfo_feb_flights %>% group_by(происхождение) %>% summarise(median_dd = median(dep_delay), iqr_dd = IQR(dep_delay), n_flights = n())
## # Таблица: 2 x 4 ## происхождение median_dd iqr_dd n_flights #### 1 ЭВР 0,5 5,75 8 ## 2 JFK -2.5 15.2 60
Здесь мы сначала сгруппировали данные по происхождению , а затем
рассчитал сводную статистику .
Упражнение-4
Рассчитайте медиану и межквартильный размах для arr_delays рейсов в sfo_feb_flights кадр данных, сгруппированный по перевозчику. Который
у перевозчика самая изменчивая задержка прибытия?
Ответ-4:
sfo_feb_flights %>% group_by(перевозчик) %>% summarise(median_ad = median(arr_delay), iqr_ad = IQR(arr_delay), n_flights = n())
## # Набор символов: 5 x 4 ## перевозчик median_ad iqr_ad n_flights #### 1 АА 5 17,5 10 ## 2 В6 -10,5 12,2 6 ## 3 ДЛ -15 22 19## 4 УА -10 22 21 ## 5 VX -22,5 21,2 12
Перевозчики DL и UA связаны между собой из-за наиболее изменчивого прибытия
задержки, потому что их межквартильные диапазоны привязаны к самому высокому в
22. 00. Это говорит о том, что они демонстрируют наибольшую вариацию в прибытии.
задержки для средних 50% их данных.
00. Это говорит о том, что они демонстрируют наибольшую вариацию в прибытии.
задержки для средних 50% их данных.
Задержки отправлений по месяцам
В каком месяце ожидается наибольшая средняя задержка вылет из аэропорта Нью-Йорка?
Давайте подумаем, как мы могли бы ответить на этот вопрос:
Сначала рассчитаем среднемесячные значения задержек отправлений. С новый язык, который мы изучаем, мы могли бы
- группа_по месяцам, затем
- обобщает средние задержки отправления.
Тогда можно было бы упорядочить эти средние задержки по убыванию заказ
nycрейсы %>% group_by(месяц) %>% суммировать (mean_dd = среднее (dep_delay)) %>% упорядочить (описание (mean_dd))
## # Таблица: 12 x 2 ## месяц mean_dd ## <целое>## 1 7 20,8 ## 2 6 20,4 ## 3 12 17,4 ## 4 4 14,6 ## 5 3 13,5 ## 6 5 13,3 ## 7 8 12,6 ## 8 2 10,7 ## 9 1 10,2 ## 10 9 6,87 ## 11 11 6. 10 ## 12 10 5.88
 10
## 12 10 5.88
10
## 12 10 5.88 Упражнение 5
Предположим, вам очень не нравятся задержки отправления и вы хотите запланировать ваше путешествие за месяц, что сводит к минимуму вашу потенциальную задержку вылета покидая Нью-Йорк. Один из вариантов — выбрать месяц с наименьшим средним значением. задержка вылета. Другой вариант — выбрать месяц с наименьшим средняя задержка отправления. Каковы плюсы и минусы этих двух выбор?
Ответ-5:
Mean Pro: представляет собой общую среднюю задержку отправления с учетом учитывать эффект каждой задержки и давать представление о том, как данные распределяются. Против: это может быть искажено выбросами.
Median Pro: принимает среднее значение всего набора данных, поэтому выбросы не искажают медиану. Против: он не может представить, как данные распространяется.
Скорость отправления вовремя для аэропортов Нью-Йорка
Предположим, мы вылетаем из Нью-Йорка и хотим знать, какой из
три крупных аэропорта Нью-Йорка имеют лучший показатель своевременности отправления
вылетающие рейсы. Также предполагается, что для нас рейс, который задерживается
менее 5 минут в основном «вовремя».
задерживается на 5 минут или более «задерживается».
Также предполагается, что для нас рейс, который задерживается
менее 5 минут в основном «вовремя».
задерживается на 5 минут или более «задерживается».
Для того, чтобы определить, в каком аэропорту лучшее время вылета скорости, мы можем
- сначала классифицировать каждый рейс как «вовремя» или «задержка»,
- , затем сгруппируйте рейсы по аэропорту отправления,
- , затем рассчитайте скорость вылета по времени для каждого аэропорта отправления,
- и, наконец, расположите аэропорты в порядке убывания времени процент выезда.
Начнем с классификации каждого рейса как «выполненного вовремя» или «задержанного» на создание новой переменной с помощью функции mutate.
nycflights <- nycflights %>% mutate (dep_type = ifelse (dep_delay < 5, «вовремя», «с задержкой»)) nycflights %>% group_by(происхождение) %>% summarise(ot_dep_rate = sum(dep_type == "вовремя") / n()) %>% упорядочить (описание (ot_dep_rate))
## # Тиббл: 3 x 2 ## происхождение ot_dep_rate #### 1 LGA 0,728 ## 2 Кеннеди 0,694 ## 3 EWR 0.
 637
637 Первым аргументом функции mutate является имя
новая переменная, которую мы хотим создать, в данном случае dep_type .
Тогда, если dep_delay < 5 , мы классифицируем рейс как "вовремя" и "с задержкой" если нет, т.е.
рейс задерживается на 5 и более минут.
Обратите внимание, что мы также перезаписываем фрейм данных nycflights с помощью новая версия этого фрейма данных, которая включает новый dep_type переменная.
Мы можем обработать все оставшиеся шаги в одном куске кода:
nycflights %>% group_by(происхождение) %>% summarise(ot_dep_rate = sum(dep_type == "вовремя") / n()) %>% организовать(desc(ot_dep_rate))
## # Набор символов: 3 x 2 ## происхождение ot_dep_rate #### 1 LGA 0,728 ## 2 Кеннеди 0,694 ## 3 EWR 0,637
Упражнение 6
Если бы вы выбирали аэропорт просто на основе времени вылета процент, из какого аэропорта Нью-Йорка вы бы вылетели?
Ответ-6:
ggplot(data = nycflights, aes(x = origin, fill = dep_type)) + geom_bar()
LGA имеет лучший процент времени отправления 72,8%. Так же
сегментированная гистограмма ниже показывает, что LGA имеет наилучшую пропорцию
рейсы вылетают вовремя. Так что я бы выбрал LGA.
Так же
сегментированная гистограмма ниже показывает, что LGA имеет наилучшую пропорцию
рейсы вылетают вовремя. Так что я бы выбрал LGA.
Упражнение 7
Измените фрейм данных, чтобы он включал новую переменную, которая
содержит среднюю скорость, avg_speed пройденную самолетом
за каждый полет (в милях в час). Подсказка: Средняя скорость может быть
рассчитывается как расстояние, деленное на количество часов в пути, и обратите внимание
что «эфирное время» указано в минутах.
Ответ-7:
nycflights <- nycflights %>% мутировать (средняя_скорость = 60 * (расстояние / воздушное_время)) проблеск (nycflights)
## Строки: 32 735 ## Столбцы: 18 ## $ year2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013, ~ ## $ месяц 6, 5, 12, 5, 7, 1, 12, 8, 9, 4, 6, 11, 4, 3, 10, 1, 2, 8, 10~ ## $ день 30, 7, 8, 14, 21, 1, 9, 13, 26, 30, 17, 22, 26, 25, 21, 23, ~ ## $ dep_time 940, 1657, 859, 1841, 1102, 1817, 1259, 1920, 725, 1323, 940~ ## $ dep_delay 15, -3, -1, -4, -3, -3, 14, 85, -10, 62, 5, 5, -2, 115, -4, ~ ## $ arr_time 1216, 2104, 1238, 2122, 1230, 2008, 1617, 2032, 1027, 1549, ~ ## $ arr_delay -4, 10, 11, -34, -8, 3, 22, 71, -8, 60, -4, -2, 22, 91, -6, ~ ## $ Carrier "VX", "DL", "DL", "DL", "9E", "AA", "WN", "B6", "AA", "EV", ~ ## $ tailnum "N626VA", "N3760C", "N712TW", "N914DL", "N823AY", "N3AXAA", ~ ## $ рейс 407, 329, 422, 2391, 3652, 353, 1428, 1407, 2279, 4162, 20, ~ ## $ origin "JFK", "JFK", "JFK", "JFK", "LGA", "LGA", "EWR", "JFK", "LGA~ ## $ dest "LAX", "SJU", "LAX", "TPA", "ORF", "ORD", "HOU", "IAD", "MIA~ ## $ air_time 313, 216, 376, 135, 50, 138, 240, 48, 148, 110, 50, 161, 87,~ ## $ расстояние 2475, 1598, 2475, 1005, 296, 733, 1411, 228, 1096, 820, 264,~ ## $ час 9, 16, 8, 18, 11, 18, 12, 19, 7, 13, 9, 13, 8, 20, 12, 20, 6~ ## $ minute 40, 57, 59, 41, 2, 17, 59, 20, 25, 23, 40, 20, 9, 54, 17, 24~ ## $ dep_type "с задержкой", "вовремя", "вовремя", "вовремя", "вовремя", "на t~ ## $ avg_speed 474.
 4409, 443.8889, 394.9468, 446.6667, 355.2000, 318.6957, ~
4409, 443.8889, 394.9468, 446.6667, 355.2000, 318.6957, ~ Упражнение 8
Постройте диаграмму рассеяния avg_speed против расстояния . Опишите взаимосвязь между средним
скорость и расстояние. Подсказка: Использовать геом_точка() .
Ответ-8:
ggplot(data = nycflights, aes(x = расстояние, y = avg_speed)) + geom_point()
Диапазон скоростей немного увеличивается с расстоянием. Причина может быть что при более длинных дистанциях время старта и посадки не считается так тяжелый, как на коротких дистанциях. Есть один исключительно быстрый полет от Ла Гуардиа до Атланты. Очень дальние расстояния полета (точки на расстояние 5.000 миль) из Нью-Йорка в Гонолулу (HNL), кратчайший путь до Филадельфии (PHL).
Упражнение 9
Воспроизведите следующий график. Подсказка: построен только фрейм данных.
содержит рейсы авиакомпаний American Airlines, Delta Airlines и United Airlines.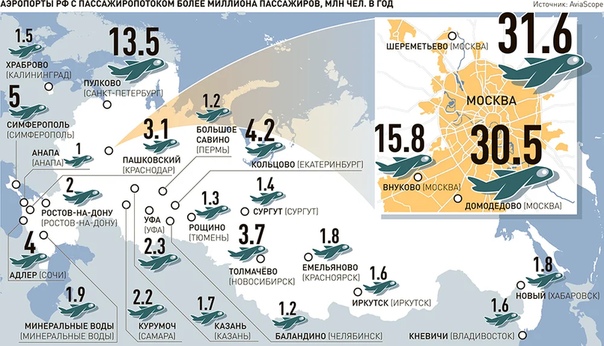 Авиакомпании, а точки
Авиакомпании, а точки colore d by носитель . Как только вы воспроизведете сюжет, определите (примерно)
какова точка отсечки для задержек вылета, когда вы все еще можете ожидать
чтобы добраться до места назначения вовремя.
Ответ-9:
nycflights_3carriers <- nycflights %>% filter(перевозчик == "AA" | перевозчик == "DL" | перевозчик == "UA") ggplot(data = nycflights_3carriers, aes(x = dep_delay, y = arr_delay, color= Carrier)) + geom_point()
Исходя из диаграммы рассеяния выше, точка отсечки для отправления
задержки, вы все еще можете РАЗУМНО ожидать прибытия в пункт назначения
время немного опережает график, примерно первые пять минут до
время отправления. Мы видим, что при 60-минутном опоздании на вылет
еще можно было прибыть в пункт назначения вовремя, но это
невероятно редкий. Это также необычно для рейсов, вылетающих между 0 и
опоздание на 60 минут. Даже большинство рейсов, вылетающих вовремя, прибывают
поздно для этих трех перевозчиков.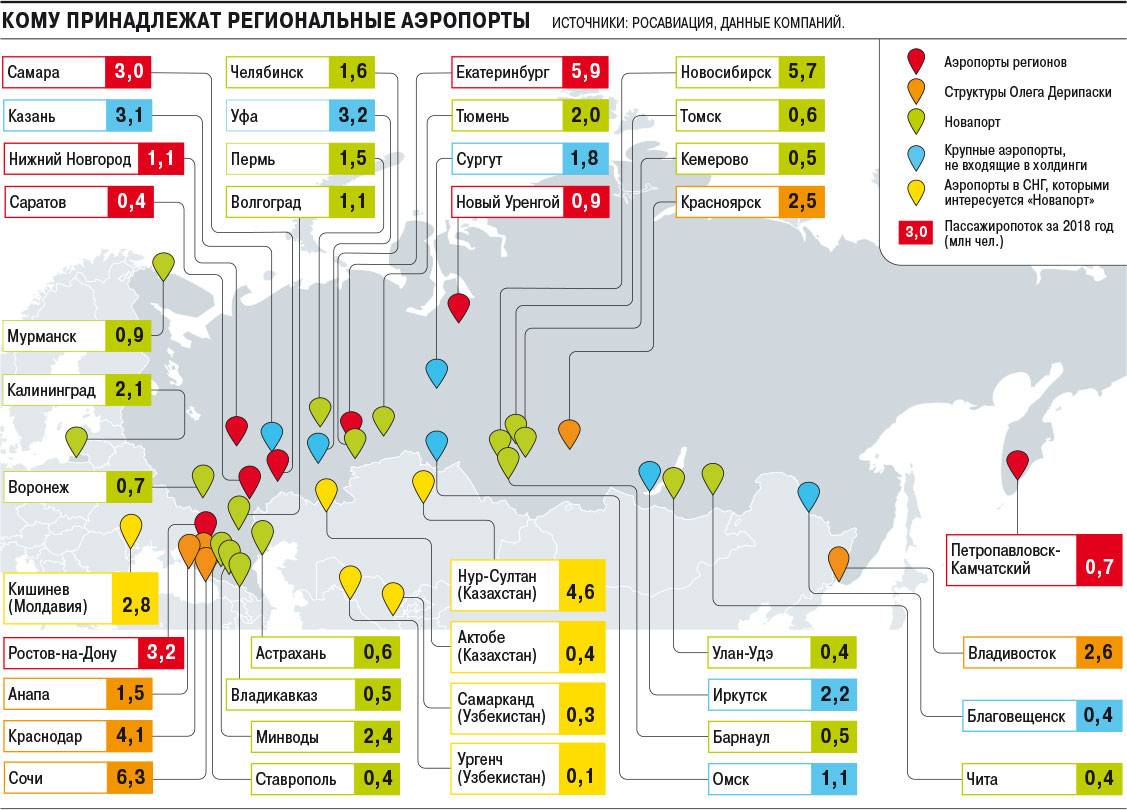 Только уйдя пораньше, вы можете рассчитывать на
прибывают вовремя, и разумное ограничение для этого, кажется, составляет около пяти
минут до запланированного взлета.
Только уйдя пораньше, вы можете рассчитывать на
прибывают вовремя, и разумное ограничение для этого, кажется, составляет около пяти
минут до запланированного взлета.
Это домашнее задание касается данных о полетах авиакомпаний из разных аэропортов. в Нью-Йорке (NYC). Мы видим несколько гистограмм задержки вылета время с разной шириной бина для извлечения большого количества информации. Мы замечаем, что чем меньше ширина ячейки, тем мельче детализация. В то время как мы видим гистограмма задержанного прибытия, проверьте распределение со сводкой статистика для другого оператора. Перевозчики DL и UA привязаны к имеют самую изменчивую задержку прибытия, потому что их межквартильные диапазоны привязаны к максимуму в 22.00. Мы попытались визуализировать связь между средней скоростью авиакомпаний и расстоянием. Скорость дальность немного увеличивается с расстоянием.
Изучение Python Data Analytics на примере — Задержки прибытия авиакомпаний | by Nick Cox
Увлекательный проект и подробное пошаговое руководство по анализу данных, которое поможет вам изучить Python, pandas, matplotlib и Basemap 2021
Фото автора CHUTTERSNAP на Unsplash Работая над получением степени магистра бизнес-аналитики, я обнаружил, что обучение на примерах — лучший способ научиться анализу данных Python. Получить набор данных и набор задач по кодированию гораздо полезнее, чем читать учебник или слушать профессора.
Получить набор данных и набор задач по кодированию гораздо полезнее, чем читать учебник или слушать профессора.
Я хочу поделиться этим методом обучения с теми, кому он тоже будет полезен. Все, что вам нужно, — это среда разработки Python (я рекомендую Jupyter Notebook) и желание учиться и получать удовольствие.
В эту статью включен список задач по анализу данных, за которым следует подробное пошаговое руководство по выполнению задач. Пожалуйста, попробуйте выполнить задания самостоятельно, прежде чем читать пошаговое руководство — так вы получите больше пользы. Имейте в виду, что существует множество способов решения проблем с кодированием, поэтому ваш код, скорее всего, не будет соответствовать моему дословно, и это нормально.
Пожалуйста, также ознакомьтесь: Изучите Python Data Analytics на примере: NYC Parking Violations
Для этого проекта мы будем использовать набор данных из примерно 40 000 записей, которые представляют задержки прибытия рейсов 18 авиакомпаний в США. Каждая строка в наборе данных представляет собой сводку данных о задержках для пары перевозчик-аэропорт за указанный месяц. Набор данных был создан в январе 2021 года и содержит данные за период с 1 января 2018 года по 31 декабря 2019 года, полученные от Бюро транспортной статистики.
Каждая строка в наборе данных представляет собой сводку данных о задержках для пары перевозчик-аэропорт за указанный месяц. Набор данных был создан в январе 2021 года и содержит данные за период с 1 января 2018 года по 31 декабря 2019 года, полученные от Бюро транспортной статистики.
Вам нужно будет установить библиотеки pandas, matplotlib и Basemap, если у вас их еще нет.
Выполните следующие задачи в Python, используя наборы данных delays_2018.csv , delays_2019.csv и airport_coordinates.csv , доступные в репозитории GitHub.
- Считайте файлы CSV, содержащие данные о задержке авиакомпании, в один кадр данных. Затем отобразите общее количество импортированных строк.
- Изменить дату 9Столбец 0488 до даты в формате ГГГГ-М (например, 2018–1). Затем выполните исследовательский анализ данных в импортированном наборе данных, чтобы выявить недопустимые данные — напишите код для удаления затронутых строк. Наконец, отобразите количество оставшихся строк.
- Показать список всех аэропортов Теннесси, которые появляются в наборе данных.
- Импортируйте набор данных координат и объедините его с существующим набором данных. Нанесите на карту координаты всех аэропортов (подсказка: используйте Matplotlib и Basemap).
- Показать количество измененных рейсов для каждой пары перевозчик-аэропорт.
- Показать, сколько прибывших в JFK в 2019 г. столкнулись с задержкой как из-за погодных условий, так и из-за перевозчика.
- Показать авиалинию с наибольшим количеством отмен рейсов в процентах от общего числа прибывающих рейсов.
- Определите общее среднее количество задержек в аэропорту.
- Показать трех перевозчиков с наименьшим количеством задержанных рейсов.
- Запросить пользователя ввести авиакомпанию. Затем нанесите ежемесячное количество минут задержки национальной воздушной системы (NAS) для этой авиакомпании. Отображение увеличения или уменьшения тенденции за последние 2 месяца.


Каждая строка в наборах данных представляет сводку данных о задержках для пары перевозчик-аэропорт за указанный месяц. Например, строка может представлять данные о задержке рейсов American Airlines, прибывающих в аэропорт имени Джона Кеннеди в Нью-Йорке, за май 2018 года.
Если одному задержанному рейсу назначено несколько причин, каждая причина оценивается пропорционально количеству задержек в минутах, за которое она отвечает. Цифры округлены и могут не совпадать с общей суммой.
Фото Джонни Коэна на UnsplashКоличество строк: 41177
Объяснение кода:
Начнем с того, что сделаем содержимое модуля pandas доступным для нашей программы. pandas — это простой в использовании инструмент для анализа и обработки данных с открытым исходным кодом, созданный на основе языка программирования Python. Мы будем широко использовать его на протяжении всего проекта.
import pandas as pd
Мы импортируем содержимое файла delays_2018. csv , вызывая метод read_csv() и сохраняя его в DataFrame с именем df_18 . DataFrame — это двумерная структура данных с помеченными осями, состоящая из данных, строк и столбцов. Думайте об этом как о таблице, созданной в Microsoft Excel или Microsoft Access. Затем мы повторяем то же действие для файла delays_2019.csv , назвав его df_19 .
csv , вызывая метод read_csv() и сохраняя его в DataFrame с именем df_18 . DataFrame — это двумерная структура данных с помеченными осями, состоящая из данных, строк и столбцов. Думайте об этом как о таблице, созданной в Microsoft Excel или Microsoft Access. Затем мы повторяем то же действие для файла delays_2019.csv , назвав его df_19 .
df_18 = pd.read_csv('delays_2018.csv')
df_19 = pd.read_csv('delays_2019.csv') Чтобы объединить два кадра данных в один кадр данных, мы вызываем метод concat() панд, который сокращение от конкатенации. Мы передаем два параметра: первый — это список, содержащий имена двух фреймов данных, которые мы хотим объединить, а второй говорит пандам игнорировать существующие индексы в двух фреймах данных, создавая таким образом новый.
df = pd.concat([df_18, df_19], ignore_index=True)
Мы используем функцию print() для печати строки «Количество строк:», за которой следует количество строк в DataFrame. Параметр, который мы передаем функции print(), состоит из двух частей. Первая — это строка «Количество строк:», заключенная в одинарные кавычки, обозначающая ее как строку. Вторая часть параметра вычисляет количество строк в df . Мы используем функцию len(), чтобы сообщить нам количество строк в df , затем оберните его вызовом метода str() для преобразования длины в строку. Наконец, + объединяет (или соединяет) две части строки вместе. Все части параметра, передаваемого функции print(), должны иметь строковый тип.
Параметр, который мы передаем функции print(), состоит из двух частей. Первая — это строка «Количество строк:», заключенная в одинарные кавычки, обозначающая ее как строку. Вторая часть параметра вычисляет количество строк в df . Мы используем функцию len(), чтобы сообщить нам количество строк в df , затем оберните его вызовом метода str() для преобразования длины в строку. Наконец, + объединяет (или соединяет) две части строки вместе. Все части параметра, передаваемого функции print(), должны иметь строковый тип.
print('Number of Rows: ' + str(len(df))) Следующие данные считаются недействительными:
- Год: значения, отличные от 2018 или 2019 прибывающих рейсов (пустые значения в arr_flights столбец)
- Перевозчик: пустые значения
- Аэропорт: пустые значения
Количество строк: 41077
Объяснение кода:
Прежде чем искать неверные данные, мы собираемся преобразовать столбец даты из строковый тип данных на сегодняшний день. Для этого мы вызываем метод to_datetime() панд. В качестве параметров мы передаем существующий столбец даты и формат дат, даже несмотря на то, что они хранятся в виде строк. %Y-%m представляет собой YYYY-M, например 2018–1. Если бы мы остановились на этом, панды отформатировали бы дату с указанием года, месяца, дня и времени, чего мы не хотим. Чтобы избежать этого, мы используем .dt.strftime('%Y-%m'), чтобы задать нужный нам формат даты.
Для этого мы вызываем метод to_datetime() панд. В качестве параметров мы передаем существующий столбец даты и формат дат, даже несмотря на то, что они хранятся в виде строк. %Y-%m представляет собой YYYY-M, например 2018–1. Если бы мы остановились на этом, панды отформатировали бы дату с указанием года, месяца, дня и времени, чего мы не хотим. Чтобы избежать этого, мы используем .dt.strftime('%Y-%m'), чтобы задать нужный нам формат даты.
df['date'] = pd.to_datetime(df['date'], format='%Y-%m').dt.strftime('%Y-%m') Нам нужно подмножество df для фильтрации записей с неверными данными. Мы можем применить несколько параметров одновременно, заключив каждый в круглые скобки и используя символ & между ними. Мы используем >= для представления больше или равно и <= для представления меньше или равно. Для столбцов рейсов прибытия, перевозчика, имени перевозчика, аэропорта и названия аэропорта нам нужно проверить нулевые значения, вызвав метод notnull().
df = df[(df['date'] >= '2018-01') & (df['date'] <= '2019-12') & (df['arr_flights'].notnull())
& (df['carrier'].notnull()) & (df['carrier_name'].notnull())
& (df['airport'].notnull()) & (df['airport_name']. notnull())]
Мы используем функцию print() точно так же, как в шаге 1 выше.
print('Number of Rows: ' + str(len(df))) Аэропорты Теннесси:
{'Чаттануга, Теннесси: Ловелл Филд', 'Мемфис, Теннесси: Мемфис Интернэшнл', 'Бристоль/Джонсон-Сити/ Кингспорт, Теннесси: Три Города», «Нэшвилл, Теннесси: Нэшвилл Интернэшнл», «Ноксвилл, Теннесси: МакГи Тайсон»}
Объяснение кода:
Для начала нам нужно идентифицировать строки в наборе данных с рейсами, прибывающими в аэропорт Теннесси. Для этого нам нужно применить функцию вдоль оси DataFrame. Поскольку мы не указываем ось, по умолчанию она равна 0, что является индексом. Поэтому мы будем перебирать столбец с названием аэропорта.
Лямбда-функция вызывает метод find() для каждого имени аэропорта, чтобы найти в нем подстроку TN . Если подстрока TN не найден в названии аэропорта, значение -1 помещается в новый столбец TN. Если найдено TN , в столбец TN помещается целое число, отличное от -1.
Если подстрока TN не найден в названии аэропорта, значение -1 помещается в новый столбец TN. Если найдено TN , в столбец TN помещается целое число, отличное от -1.
df['TN'] = df['airport_name'].apply(lambda x: x.find('TN')) Теперь, когда мы определили все аэропорты в Теннесси, нам нужно создать список из них, но без дубликатов. Для этого мы можем использовать функцию set(), и в качестве параметра мы передаем подмножество DataFrame, содержащее только строки с именами аэропортов, содержащие TN , обозначенный цифрой -1 в столбце TN.
airports = set(df[df['TN'] != -1]['airport_name'])
Затем мы распечатываем список аэропортов Теннесси.
print('Аэропорты Теннесси:')
print(аэропорты) Объяснение кода:
Пожалуйста, потерпите меня, так как есть много кода, который требует объяснения. Усилия того стоят, потому что вы научитесь отображать карты и наносить на них точки с помощью координат.
Импортируем содержимое airport_coordinates.csv , вызвав метод read_csv() и сохранив его в кадре данных с именем df_coords .
df_coords = pd.read_csv('airport_coordinates.csv') Теперь мы собираемся создать новый DataFrame для представления всех аэропортов в наборе данных и их координат. Мы подмножаем df , чтобы включить только столбцы для аэропорта и названия аэропорта. Добавив вызов функции drop_duplicates(), мы можем создать DataFrame, в котором каждый аэропорт встречается только один раз. Наконец, вызовом функции reset_index() мы сбрасываем индекс DataFrame на исходный.
df_airports = df[['airport', 'airport_name']].drop_duplicates().reset_index(drop=True)
Now, we use the merge() function of pandas to merge the df_airport and df_coords DataFrames для создания нашего окончательного DataFrame аэропортов с их соответствующими координатами. Первые два параметра — это кадры данных, которые мы объединяем, а третий — столбец, общий для обоих кадров данных — аэропорт, который представляет собой трехсимвольный указатель аэропорта прибытия.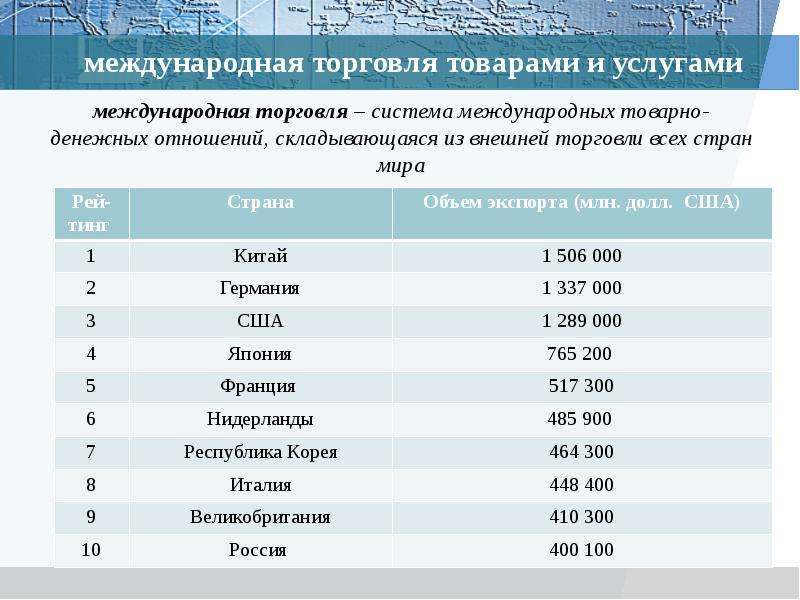
df_airports = pd.merge(df_airports, df_coords, on='airport')
Следующая строка кода может вам понадобиться или не понадобиться. Я столкнулся с ошибкой при запуске из строки кода mpl_toolkits.basemap import Basemap , и решение заключалось в том, чтобы добавить следующее.
import os
os.environ["PROJ_LIB"] = "C:\\Users\\Nick\\anaconda3\\envs\\sandbox\\Library\\share\\basemap";
Мы делаем содержимое библиотеки matplotlib доступным для нашей программы. matplotlib — это обширная библиотека для создания визуализаций в Python.
Затем мы делаем библиотеку mpl_toolkits.basemap доступной для нашей программы. Basemap — это библиотека для нанесения 2D-данных на карты, которую мы будем использовать для построения карты аэропортов в наборе данных.
импортировать matplotlib.pyplot как plt
из mpl_toolkits.basemap import Basemap
Мы указываем размер нашей карты как 16 x 16. Затем мы создаем экземпляр класса Basemap, передавая большую группу параметров. Первые четыре (llcrnclon, llcrnrlat, urcrnrlon и urcrnrlat) определяют долготу нижнего левого угла, широту нижнего левого угла, долготу верхнего правого угла и широту верхнего правого угла графика. Для этого проекта мы указываем координаты, которые дают нам карту Соединенных Штатов. В качестве параметра проекта мы передаем lcc (Lambert Conformal), который обычно используется для аэронавигационных карт. Остальные параметры специфичны для выбора lcc.
Первые четыре (llcrnclon, llcrnrlat, urcrnrlon и urcrnrlat) определяют долготу нижнего левого угла, широту нижнего левого угла, долготу верхнего правого угла и широту верхнего правого угла графика. Для этого проекта мы указываем координаты, которые дают нам карту Соединенных Штатов. В качестве параметра проекта мы передаем lcc (Lambert Conformal), который обычно используется для аэронавигационных карт. Остальные параметры специфичны для выбора lcc.
Более подробное описание параметров см. в официальной документации по базовой карте.
fig = plt.figure(figsize=(16, 16))
m = Basemap(llcrnrlon=-119,llcrnrlat=22,urcrnrlon=-64,urcrnrlat=49,
проекция='lcc',lat_1=32, lat_2=45,lon_0=-95)
Приведенный выше код дает нам правильные координаты на графике, но не дает контура Соединенных Штатов и их штатов. Для этого нам нужно использовать шейп-файлы. Шейп-файлы, необходимые для этого проекта, можно найти в репозитории Basemap GitHub. Ищите st99_d00.dbf, st99_d00. shp и st99_d00.shx — поместите эти файлы в ту же папку, что и остальные исходные файлы.
shp и st99_d00.shx — поместите эти файлы в ту же папку, что и остальные исходные файлы.
Мы вызываем метод readshapefile() для нашего объекта Basemap и передаем ему два параметра. Первое — это имя загруженного нами шейп-файла, а второе — это имя, которое мы назначаем атрибуту для хранения точек карты шейп-файла.
m.readshapefile('st99_d00', name='states') Теперь нам осталось нанести координаты на карту, вызвав метод scatter() нашего объекта Basemap. Переданные параметры - координаты долготы и широты аэропортов в наших df_airports DataFrame и параметр latlon, равный True, что указывает на то, что наши координаты указаны в градусах. Мы указываем .values для передачи только значений из DataFrame, исключая, таким образом, индексы.
m.scatter(df_airports['long'].values, df_airports['lat'].values, latlon=True)
plt.show()
Объяснение кода:
теперь обратимся к другой мощной функции pandas — crosstab. Перекрестное табулирование — это метод количественного анализа взаимосвязи между несколькими переменными.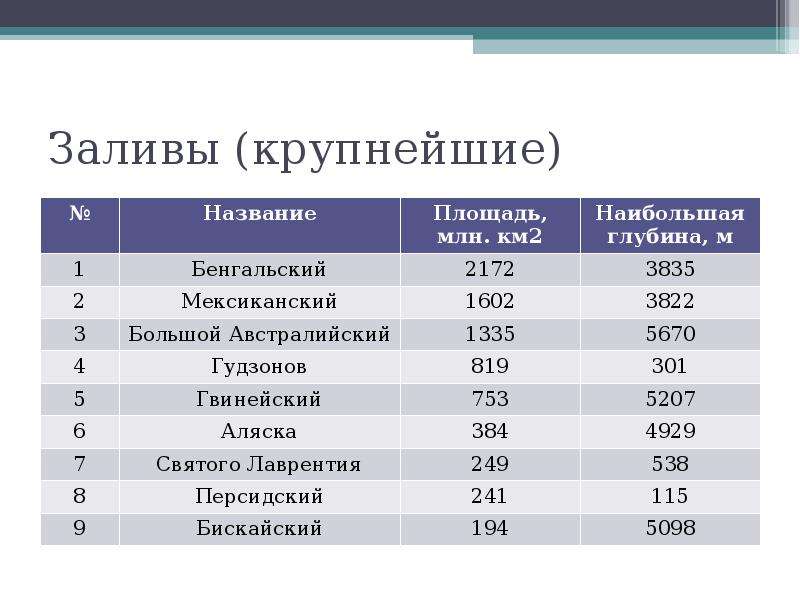 В этом проекте мы хотим определить количество отклоненных рейсов для каждой пары перевозчик-аэропорт, например: сколько рейсов American Airlines, которые должны были прибыть в аэропорт имени Джона Кеннеди в Нью-Йорке, были отклонены? Используя функцию crosstab() панд, мы можем создать единую таблицу, которая отображает это для всех пар перевозчик-аэропорт в нашем наборе данных.
В этом проекте мы хотим определить количество отклоненных рейсов для каждой пары перевозчик-аэропорт, например: сколько рейсов American Airlines, которые должны были прибыть в аэропорт имени Джона Кеннеди в Нью-Йорке, были отклонены? Используя функцию crosstab() панд, мы можем создать единую таблицу, которая отображает это для всех пар перевозчик-аэропорт в нашем наборе данных.
Первый параметр, который мы передаем, — это несущий столбец из df , который будет строками в нашей кросс-таблице. Второй — это столбец аэропорта, который будет столбцом в нашей кросс-таблице. Значения, которые мы хотим отобразить в кросс-таблице, — это количество отклоненных рейсов, столбец arr_diverted. С помощью четвертого параметра мы указываем, что хотим суммировать количество отклонений для каждой пары перевозчик-аэропорт — это необходимо, потому что каждая пара перевозчик-аэропорт появляется в наборе данных несколько раз, один раз в месяц. Наконец, мы завершаем строку кода вызовом функции fillna() для замены значений NaN пробелами — это удаляет шум из результирующей кросс-таблицы и облегчает чтение.
Всего одна строка кода, но очень мощная.
pd.crosstab(df['перевозчик'], df['аэропорт'], values=df['arr_diverted'], aggfunc='sum').fillna('') Количество задержек: 6919.429999999999
Объяснение кода:
Мы использовали аналогичный код на шаге 2 выше. Мы подмножаем df , чтобы получить только те строки, которые представляют рейсы, прибывающие в JFK в 2019 году, которые были задержаны как перевозчиком, так и погодными условиями. Мы сохраняем результат как df_f .
df_f = df[(df['date'] >= '2019-01') & (df['date'] <= '2019-12') & (df['airport'] == 'JFK')
& (df['carrier_ct'] > 0) & (df['weather_ct'] > 0)]
Общее количество задержек - это сумма задержек перевозчика и погоды, которую мы распечатываем. Помните, что нам нужно преобразовать суммы в строку, прежде чем мы сможем их распечатать.
print("Количество задержек: " + str(df_f['carrier_ct'].sum() + df_f['weather_ct'].sum())) Объяснение кода:
Чтобы рассчитать процент отмены, нам нужны кадры данных, представляющие как числитель (отмененные рейсы), так и знаменатель (все рейсы). Начнем с последнего: мы группируем строки в df по названию перевозчика и суммируем количество прибывающих рейсов для каждого перевозчика. Мы передаем параметр имени «num_arrived» в функцию reset_index(), чтобы назвать столбец, содержащий значения суммы.
Начнем с последнего: мы группируем строки в df по названию перевозчика и суммируем количество прибывающих рейсов для каждого перевозчика. Мы передаем параметр имени «num_arrived» в функцию reset_index(), чтобы назвать столбец, содержащий значения суммы.
Затем мы группируем строки в df по названию перевозчика и суммируем количество отмененных прибытий для каждого перевозчика. Мы снова используем reset_index(). Наконец, мы создаем df_cancelled DataFrame путем слияния DataFrame с использованием общего столбца «carrier_name».
df_flights = df.groupby('carrier_name')['arr_flights'].sum().reset_index(name='num_arrived')
df_cancelled = df.groupby('carrier_name')['arr_cancelled'].sum() .reset_index(name='num_cancelled')
df_cancelled = pd.merge(df_cancelled, df_flights, on='carrier_name') Затем мы можем рассчитать процент отмененных рейсов для каждого перевозчика, разделив количество отмененных рейсов на количество прибывающих рейсов каждого перевозчика.
df_cancelled['proportion'] = df_cancelled['num_cancelled'] / df_cancelled['num_arrived'] * 100
В качестве последнего шага мы сортируем значения в порядке убывания, вызывая функцию sort_values() и затем используя head( 1) отображать только перевозчика с наибольшим процентом отмененных рейсов.
df_cancelled.sort_values(by=['proportion'], по возрастанию=False).head(1)
Среднее количество задержек на аэропорт: 7544,997245179064
Объяснение кода:
Чтобы рассчитать общее среднее количество задержек на аэропорт, нам сначала нужно рассчитать количество задержек на аэропорт, а затем найти среднее значение этих значений. Мы можем добиться этого в одной строке кода. Мы группируем строки в df по аэропортам и суммируем количество задержанных прибытий в каждый аэропорт. Добавляя вызов функции mean() в конце, мы вычисляем среднее значение сумм.
avg_delays = df.groupby('airport')['arr_del15'].sum().mean() Затем мы просто распечатываем результат.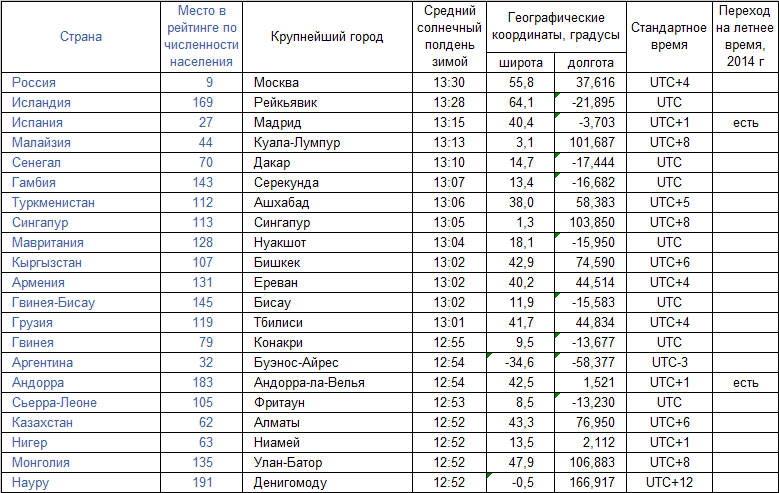
print('Среднее количество задержек в аэропорту: ' + str(avg_delays)) Объяснение кода:
Мы группируем строки в df по перевозчикам и суммируем количество задержек прибытия на перевозчика. Нас интересуют только три перевозчика с наименьшим количеством задержек прибытия, поэтому используйте .nsmallest(3), чтобы получить три перевозчика с наименьшим количеством. В целях отображения мы передаем параметр имени в нашем вызове reset_index().
df.groupby('carrier')['arr_del15'].sum().nsmallest(3).reset_index(name='num_delays') Какая авиакомпания (9E, AA, AS, B6, DL, EV, F9, G4, HA, MQ, NK, OH, OO, UA, VX, WN, YV, YX)? EV
Общее количество минут задержки NAS для EV увеличивается.
Объяснение кода:
Мы используем input(), чтобы попросить пользователя ввести перевозчика и сохранить значение в переменной авиакомпании . Чтобы сделать код простым, мы не выполняем никаких проверок того, что вводит пользователь, и поэтому мы ожидаем, что он будет вводить только допустимое значение.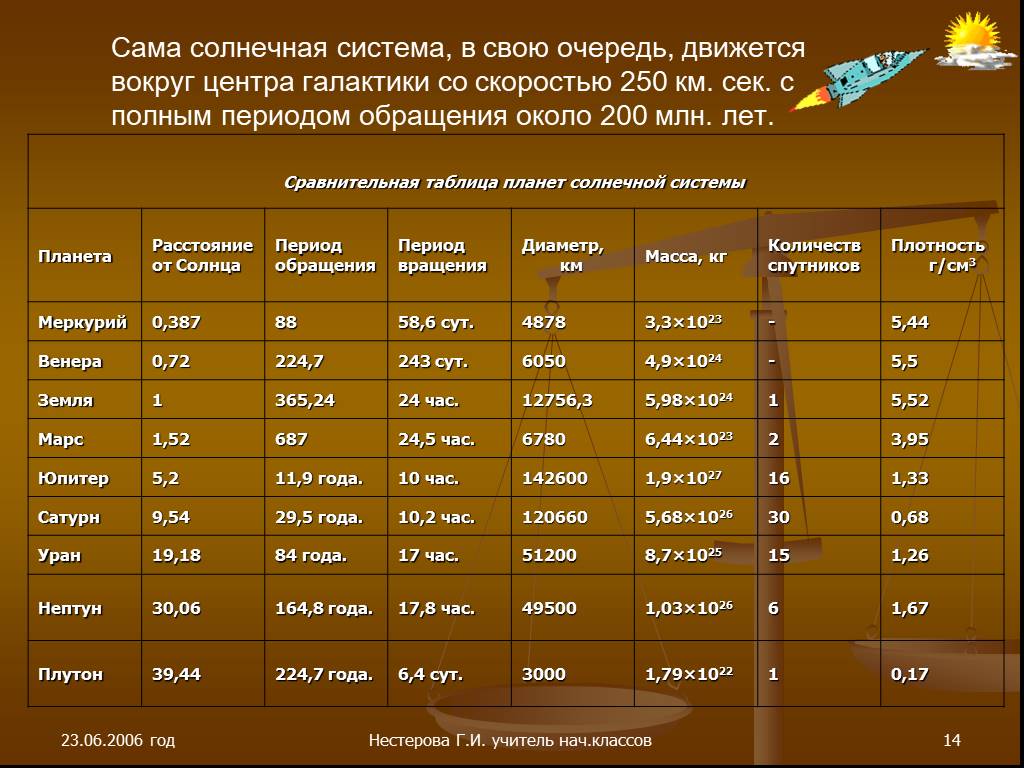
авиакомпания = ввод("Какая авиакомпания (9E, AA, AS, B6, DL, EV, F9, G4, HA, MQ, NK, OH, OO, UA, VX, WN, YV, YX)? ") Мы подмножаем df в соответствии с оператором, введенным пользователем, и, поскольку нас интересуют только задержки национальной воздушной системы (NAS), мы также фильтруем их, чтобы исключить строки без каких-либо задержек NAS. Мы сохраняем результат как . df_nas .
df_nas = df[(df['carrier'] == авиакомпания) & (df['nas_delay'] > 0)]
Мы группируем строки в df_nas по дате и суммируем количество NAS задержки за каждый месяц
df_nas = df_nas.groupby('date')['nas_delay'].sum() Теперь пришло время построить результаты с помощью matplotlib. Мы указываем 16 x 8 в качестве размера графика, df_nas в качестве источника данных для графика, и, поскольку на оси X много меток, мы поворачиваем их на 85 градусов, чтобы они отображались аккуратно, без перекрытий.
plt.figure(figsize=(16, 8))
plt.